The DeLeAn rubrics consider 7 broad capabilities from Tolan et al. (2021) grounded in cognitive science and applicable to LLMs, and add subdimensions (leading to 11). It also includes domain ‘knowledge’ (with 5 subdimensions) and 2 ‘extraneous’ dimensions: Atypicality and Volume, to account for elements that make the task more challenging independently of primordial or knowledge demands. An additional dimension, Unguessability, is computed algorithmically by considering the number of choices, instead of using a rubric.
| Dimension (Broad) | Dimension (Specific) | Description of Demands | ||
|---|---|---|---|---|
| AS | Attention and Scan | AS | Attention and Scan | Focus on or locate specific elements within a given stream of information or environment in the whole process of solving a task. |
| CE | Comprehension and Expression | CEc | Verbal Comprehension | Understand text, stories or the semantic content of other representations of ideas in different formats or modalities. |
| CEe | Verbal Expression | Generate and articulate ideas, stories, or semantic content in different formats or modalities. | ||
| CL | Conceptualisation, Learning and Abstraction | CL | Conceptualisation, Learning and Abstraction | Build new concepts, engage in inductive and analogical reasoning, map relationships between domains, and generate abstractions from concrete examples. |
| MC | Metacognition and Critical Thinking | MCr | Identifying Relevant Information | Recognise what information helps solve the task or does not, and how this recognition process unfolds as they work toward the solution. |
| MCt | Critical Thinking Processes | Monitor or regulate multiple thought processes to answer the question effectively, ranging from simple recall to high-level critical thinking. | ||
| MCu | Calibrating Knowns and Unknowns | Recognise the boundaries of one's knowledge and confidently identify what one knows they know, knows they don't know, or is uncertain about. | ||
| MS | Mind Modelling and Social Cognition | MS | Mind Modelling and Social Cognition | Model the minds of other agents or reasoning about how the beliefs, desires, intentions, and emotions of multiple other agents might interact to determine future behaviours. |
| QL | Quantitative and Logical Reasoning | QLl | Logical Reasoning | Match and apply rules, procedures, algorithms or systematic steps to premises to solve problems, derive conclusions and make decisions. |
| QLq | Quantitative Reasoning | Work with and reason about quantities, numbers, and numerical relationships. | ||
| SN | Spatial Reasoning and Navigation | SNs | Spatio-physical Reasoning | Understand spatial relationships between objects and predicting physical interactions. |
| KN | Knowledge | KNa | Knowledge of Applied Sciences | Knowledge or conceptual understanding in applied sciences (e.g., medicine, law, education, business, agriculture, engineering except IT). |
| KNc | Customary Everyday Knowledge | Knowledge in information that most people in a given society typically acquire through daily life experiences, social interactions, and media. | ||
| KNf | Knowledge of Formal Sciences | Knowledge or conceptual understanding in formal sciences (e.g., mathematics, logic, computer science, statistics). | ||
| KNn | Knowledge of Natural Sciences | Knowledge or conceptual understanding in natural sciences (e.g., physics, chemistry, biology, astronomy, earth sciences, ecology). | ||
| KNs | Knowledge of Social Sciences | Knowledge or conceptual understanding in social sciences and humanities (e.g., history, psychology, sociology, literature, art, philosophy). | ||
| AT | Atypicality | AT | Atypicality | How uncommon the task is or how unlikely it is that the instance has appeared in various sources (internet, textbooks, tests). |
| VO | Volume | VO | Volume | Proportional to the logarithm of the time a fully competent human needs to read and complete the task in ideal conditions, excluding interruptions. |
| UG | Unguessability | UG | Unguessability | The chance of error (percentage) of a task if following obvious cues or by random guess. |
Select a dimension below to view its rubric.
The ADeLe battery is obtained by running the DeLeAn rubrics on 63 tasks from 20 benchmarks, shown below. Only a subset of instances from each task was included in the benchmark (see the original paper for details).
| Civil Service Examination | LogiQA-en | 408 |
| GRE & GMAT | AQuA-RAT | 203 |
| LSAT | LSAT-AR | 187 |
| LSAT-LR | 470 | |
| LSAT-RC | 253 | |
| SAT | SAT-En | 196 |
| SAT-Math | 214 |
| Molecule Captioning | 160 |
| Molecule Design | 295 |
| Name Prediction | 476 |
| Reaction Prediction | 412 |
| Retrosynthesis | 380 |
| Data Analysis | CTA | 33 |
| Language | Connections | 29 |
| Math | AMPS Hard | 69 |
| Math Competition | 78 | |
| Olympiad | 26 | |
| Reasoning | Spatial | 34 |
| Zebra Puzzle | 22 |
| Biology | 447 |
| Business | 410 |
| Chemistry | 368 |
| Computer Science | 345 |
| Economics | 428 |
| Engineering | 296 |
| Health | 411 |
| History | 304 |
| Law | 362 |
| Math | 425 |
| Other | 429 |
| Philosophy | 402 |
| Physics | 377 |
| Psychology | 427 |
| Date | 27 |
| Diagnosis | 14 |
| Dosage | 20 |
| Lab | 180 |
| Physical | 214 |
| Risk | 84 |
| Severity | 17 |
| Algebra | 337 |
| Applied Mathematics | 302 |
| Calculus | 30 |
| Discrete Mathematics | 314 |
| Geometry | 329 |
| Number Theory | 322 |
| Precalculus | 30 |
| Chemistry | 142 |
| Math | 105 |
| Physics | 108 |
| Date Arithmetic | 493 |
| MCTACO | 205 |
| MenatQA-Counterfactual | 130 |
| MenatQA-Order | 157 |
| MenatQA-Scope | 393 |
| TempReason-L2 | 318 |
| TempReason-L3 | 339 |
| TimeDial | 340 |
| TimeQA-explicit | 379 |
| TimeQA-implicit | 348 |
| E | 344 |
| I | 371 |
| S | 340 |
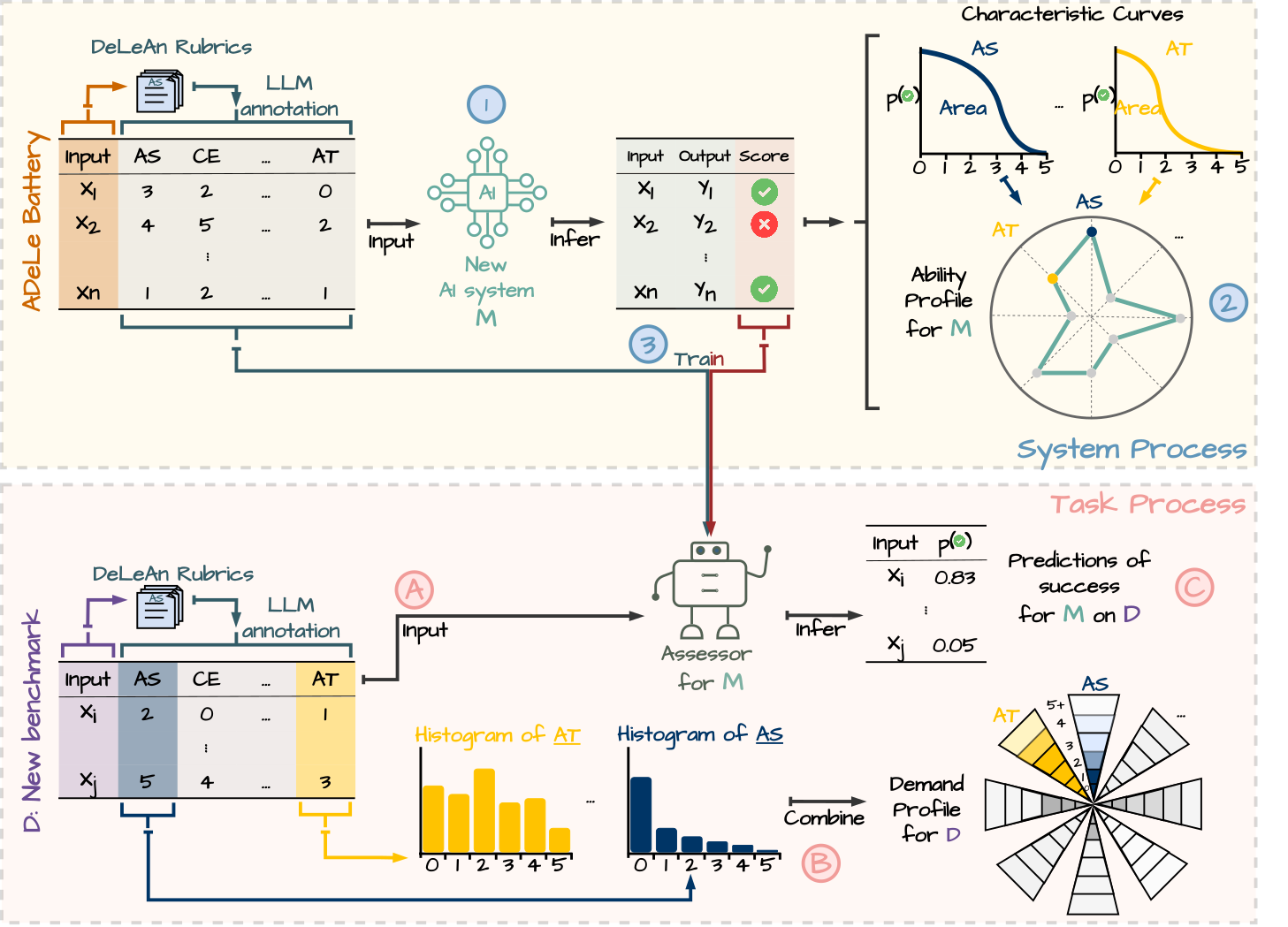
The annotations obtained with the DeLeAn rubrics allow to identify what demands the benchmarks composing ADeLe are loaded on. The following image (from the original paper) shows the overall distribution of demands on the ADeLe battery.


From the original paper.
The annotations obtained with the DeLeAn rubrics also allow to identify what demands are correlated with one another, which is important to understand what benchmarks really measure.

From the original paper.
By testing a LLM on the ADeLe benchmark, an ability “profile” can be extracted, representing an ability level for each considered dimension. The plot below shows the profile of the LLMs considered in the original paper.

From the annotated ADeLe battery and the instance-level results of a LLM, the ability value for each dimension is obtained by:
See the image below (from the original paper) for a visualization.
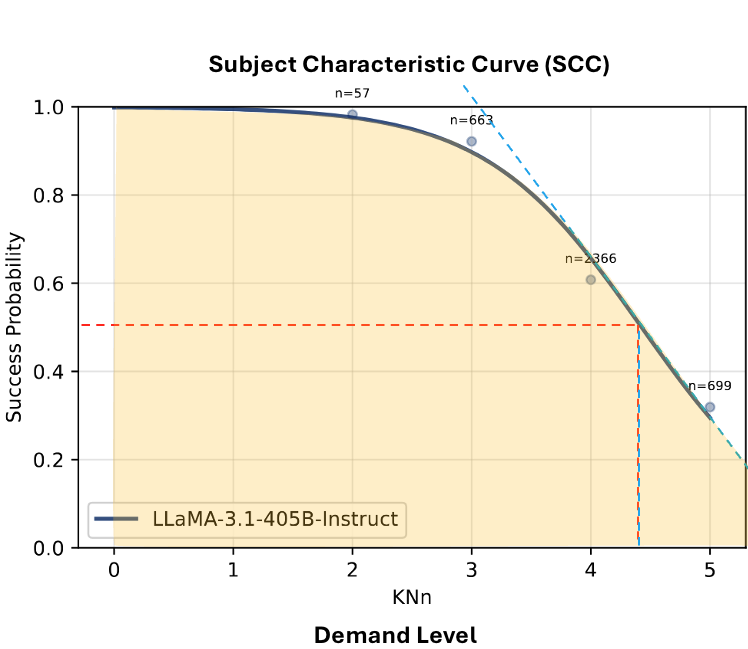
Select an LLM below to view its characteristic curves from the original paper.
We encourage and welcome inputs from others in the research community. Here are some ways you can help out:
We are working on easier ways for you to contribute directly to this initiative. In the meantime, please get in touch at jh2135 AT cam.ac.uk if you're interested in joining the effort.
Please consider citing our work if you found it useful:
@article{zhou2026general,
title={General Scales Unlock AI Evaluation with Explanatory and Predictive Power},
author={Zhou, Lexin and Pacchiardi, Lorenzo and Mart{\'i}nez-Plumed, Fernando and Collins, Katherine M. and Moros-Daval, Yael and Zhang, Seraphina and Zhao, Qinlin and Huang, Yitian and Sun, Luning and Prunty, Jonathan E. and Li, Zongqian and S{\'a}nchez-Garc{\'i}a, Pablo and Chen, Kexin Jiang and Casares, Pablo A. M. and Zu, Jiyun and Burden, John and Mehrbakhsh, Behzad and Stillwell, David and Cebrian, Manuel and Wang, Jindong and Henderson, Peter and Wu, Sherry Tongshuang and Kyllonen, Patrick C. and Cheke, Lucy and Xie, Xing and Hern{\'a}ndez-Orallo, Jos{\'e}},
journal={Nature},
year={2026},
doi={10.1038/s41586-026-10303-2},
url={https://www.nature.com/articles/s41586-026-10303-2},
}This research project has benefitted from the Microsoft Accelerate Foundation Models Research (AFMR) grant program.
We thank Álvaro D. Gómez Antón and Felix Marti-Perez for contributing with additional experiments.